OpenThoughts data generation involved a wealth of experiments, model training, and evaluations. In addition to opening the resulting dataset and models, we now release a large set of our experimental results gathered along the way and tools to analyse them in our HuggingFace spaces. Our meta-analysis of evaluation results over hundreds of models gives insight into the reasoning benchmarks.
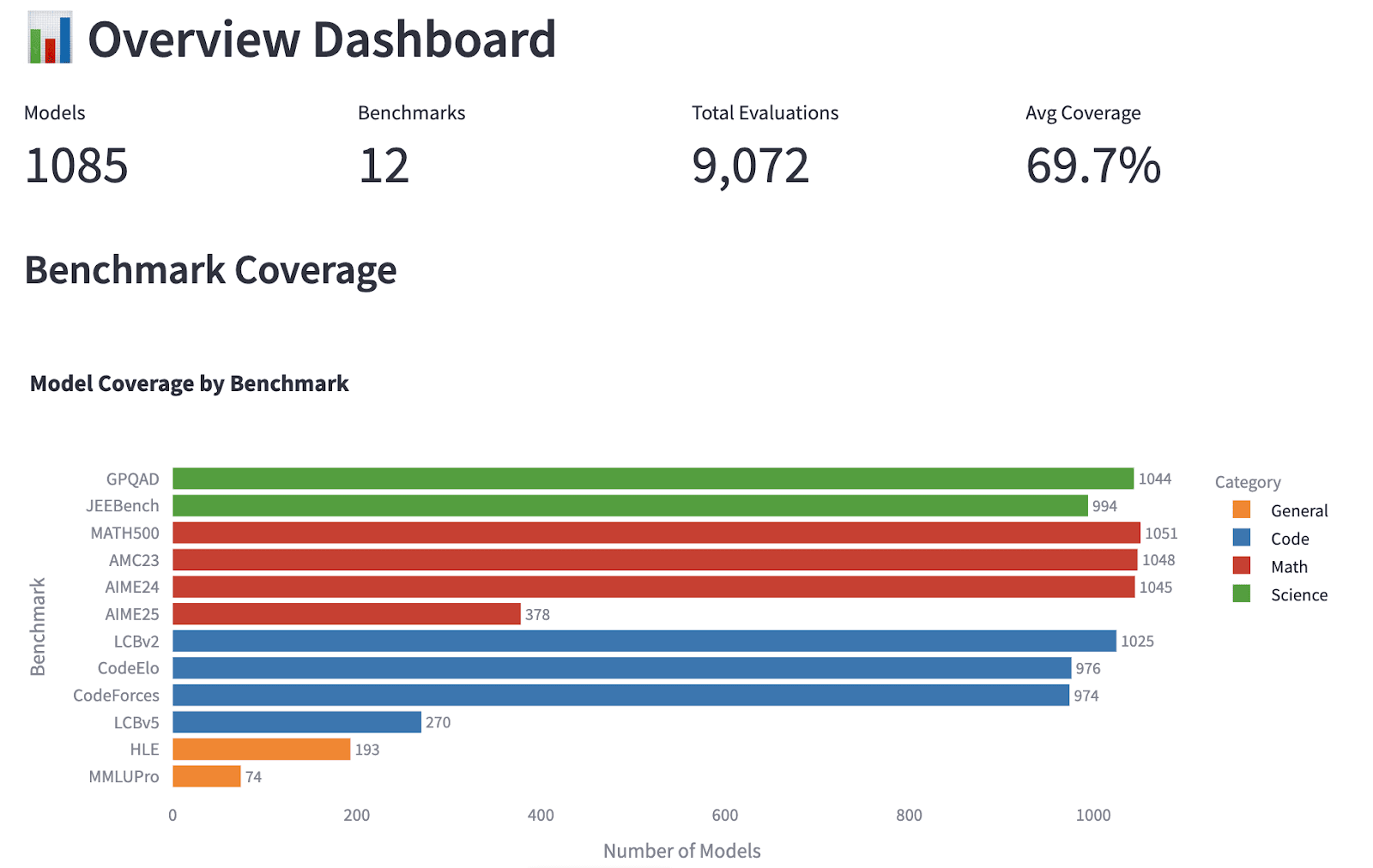
Evalchemy allowed us to run and log the evaluations of a thousand models. The data logs lead us to fascinating observations about cross-benchmark comparisons.
We consider 12 reasoning-focused benchmarks in 4 categories: Math, Code, Science, and General. The first observation is that model ranking across different benchmarks all positively correlate, and more so within the same category.
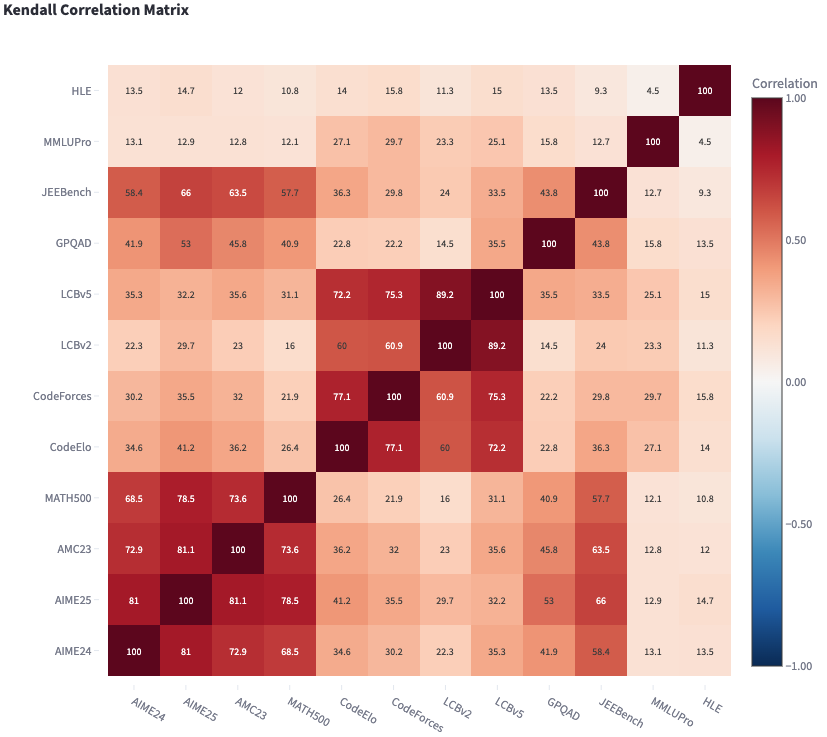
These correlations hide interesting patterns:
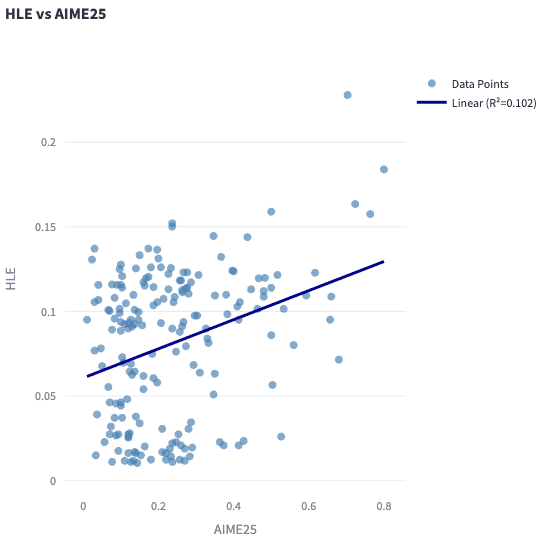
Some benchmark correlations seem extremely weak and mainly show that stronger models usually generalize, but these benchmarks measure different properties. Other benchmarks, such as AIME24 and AIME25, show robust agreement.
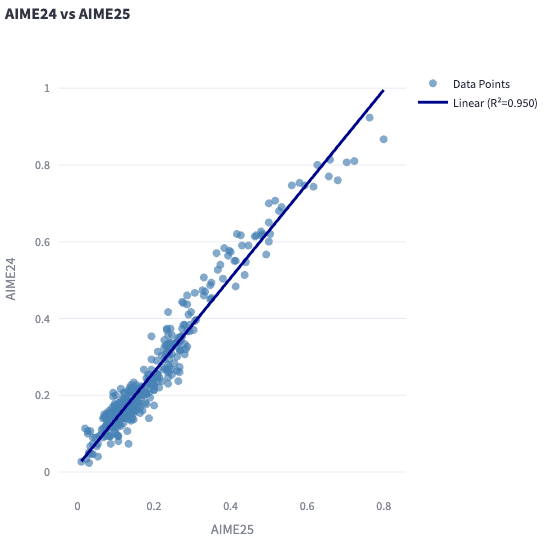
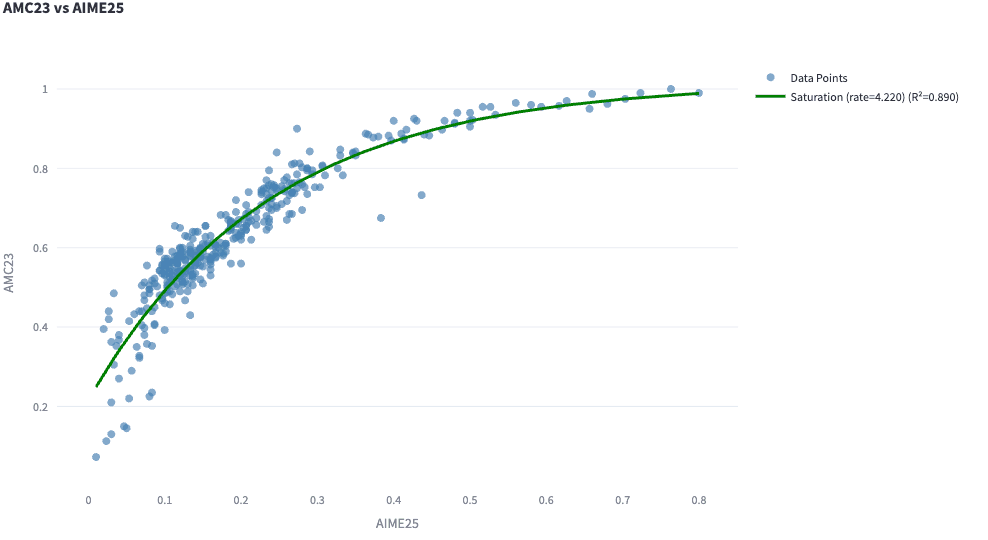
Another typical pattern shows good agreement between model rankings using two benchmarks, but the scores show signs of saturation. For example, AMC23 progress shows a diminishing return compared to AIME25. Stronger models approach a perfect score on AMC23.
Comparing other benchmarks, such as AMC23 vs JEEBench, shows other interesting patterns: the best models and the weakest models both correlate fairly strongly, but intermediate models are challenging to distinguish, resulting in a good score correlation (Pearson) but a relatively weak model ranking correlation (Kendall).
Model performance on reasoning benchmarks might be challenging to navigate. To help make sense of them, we propose a model ranking system that is robust to missing evaluation results over a selected set of benchmarks. We use median ranking over the set of benchmarks and fill in the missing rankings using Kendall correlation estimation. When considering all four categories, Gemini 2.5 Pro is at the top of the leaderboard. However, if we only consider our two science benchmarks (GPQA and JEEBench), Deepseek's new R1 model (05/28) ranks first.
Finally, you can explore result uncertainties for each benchmark and how they influence benchmark correlations.